-
As an intelligent video analysis engine for capturing, recognition and attributive analysis of faces, human bodies, motor vehicles and non-motor vehicles in videos or pictures, the fully structured video engine developed by Cloudwalk supports multiple functions such as face retrieval/clustering, human body retrieval/clustering, face and human body associative retrieval/clustering, vehicle retrieval, license plate recognition and attribute-based structured retrieval.
This video engine, with an efficient and open architecture model, stably and flexibly supports a variety of functional modules:
• Stand-alone client-server architecture to ensure stability
• An extensible plug-in system to satisfy flexible customization
• Support multiple reasoning models and an efficient heterogeneous computing platform (a variety of AI chips)
• Distributed architecture to guarantee high availability of the system
-
The original face recognition algorithm developed by Cloudwalk possesses industry-leading advantages in face detection, face comparison, 1:N face recognition and face attributes.
-
Cloudwalk in vivo detection algorithm covers many categories, e.g. active in vivo detection, silent in vivo detection, infrared in vivo detection, structured light/TOF in vivo detection and 3D in vivo detection.
The Cloudwalk in vivo detection camera based on the original core algorithm developed by Cloudwalk is the first product of its kind in China to pass the national standard test, with the in vivo detection performance reaching the highest security level (enhanced level) in the financial payment standard. Supporting infrared monocular/binocular camera for in vivo detection, the Cloudwalk in vivo detection camera achieves in live detection and face recognition algorithms on low computing platform with embedded module featuring fast startup and low power consumption as well as simplified and optimized neural network.
Cloudwalk launched its first 3D structured light face recognition technology in February 2018. Compared with the previous 2D face recognition and infrared in vivo detection technology, the 3D structured light technology has made a great leap forward in security, recognition accuracy and recognition speed. It achieves an accuracy of above 99% at an error rate of 1/1000000 and reduces the recognition time from 1-2 seconds to 1-2 milliseconds, so as to effectively defend against fraudulent means like masks and videos.
-
Adopting the deep learning model, the object detection algorithm developed by Cloudwalk leads in both algorithm and application:
• Algorithm advantage: Based on the advanced target detection algorithm of Cloudwalk and the most cutting-edge inference library, this object detection algorithm, which possesses a number of patents, remarkably optimizes the efficiency of feature extraction;
• Excellent performance: Fast recognition, high accuracy and real-time accurate feedback;
• High security: Adapting to the company’s soft and hard key authorization, the SDK layer encrypts the identification model to prevent the product from being copied;
• Strong adaptability: With great application value, this object detection algorithm is applied to scenarios such as industrial production, power operation and engineering construction to efficiently perform functions like defect detection and helmet detection.
-
The Pyramidal-FSMN speech recognition model launched by Cloudwalk has broken the world record on Librispeech, the largest open source speech recognition dataset in the world. Increasing the recognition accuracy to 97.03% and reducing the word error rate (WER) of Librispeech to 2.97%, which is an increase of 25% over the original target, the Pyramidal-FSMN speech recognition model significantly refreshed the previous record, surpassing the strictly trained professional human stenographer.
-
The Cloudwalk Pixer-Anchor text detection algorithm can identify and structurally output text information on test sets with multiple formats and interference such as complicated background, shadow, crease, seal, watermark, serial and dislocation. In ICDAR2015 and 2017 MLT, this algorithm refreshed the world record in detection accuracy and efficiency, winning the first place in many POC tests in the banking industry.
With automatic recognition training algorithm, automatic adaptation and reconstruction algorithm, automatic tagging and correction algorithm, text detection and format analysis algorithm as well as technologies such as semantic understanding and automatic integration, the Cloudwalk OCR automatic training platform automatically tags and trains pictures, and produces a text recognition model that can be used in the real environment without basic data, realizing “tagging while training”.
-
Natural language
processing
Cloudwalk has made several world-class achievements in the field of natural language processing:
Semantic perception:
By tagging the model using the pre-trained semantic role, the SemBERT semantic awareness multi-task pre-training language model jointly launched by Cloudwalk and Shanghai Jiaotong University introduces explicit context semantic label information to enhance the modeling performance of the deep language model, which significantly improves the benchmark model in terms of the 10 natural language comprehension tasks, even reaching the world’s leading level.
Machine reading comprehension:
The DCMN model, a reading information matching mechanism jointly developed by Cloudwalk and Shanghai Jiaotong University, topped the RACE dataset of a large deep reading comprehension task launched by Carnegie Mellon University, becoming the first model in the world to surpass mankind. With the DCMN model, machine reading achieved a correct rate of 72.1%, 4.2% higher than the previous best result (67.9%), and surpassed the score achieved by mankind (69.4%) for the first time in the high school test.
After that, Cloudwalk and Shanghai Jiaotong University launched DCMN+, an enhanced model based on DCMN, to adapt to the bi-directional matching strategy of multi-choice machine reading comprehension. With large-scale pre-training models like BERT as the front-end encoder, DCMN+ achieved the most advanced level in many multi-choice machine reading comprehension tasks (e.g. RACE of Carnegie Mellon University).
-
Cloudwalk possesses a complete set of knowledge graph products that cover multiple stages such as knowledge modeling, knowledge extraction, knowledge storage, knowledge computing, knowledge reasoning and knowledge application. Such knowledge graph products have many advantages, e.g. advanced concept, large capacity, excellent performance, abundant functions, convenient interaction and appropriate deployment.
Based on big data platforms and with graphic calculation as the core, our knowledge graph products help enterprise users in various fields to build their knowledge middle grounds, provide them with all-round knowledge assistance, and improve their level of intelligent operation and management.
-
Dual-mode heterogeneous
intelligent scorecard
Cloudwalk has made a number of significant functional breakthroughs in this field:
The model can automatically search and mine features. With the search strategy manually configured, the model is able to automatically process and screen features to find the most effective feature combination, and apply the automatic feature engineering to mine feature combinations and bin the features, without manually selecting the features and adjusting the binning. Users only need to define the search range of model parameters, and the algorithm can automatically search and adjust the optimal model parameters. Using the decision-making tree for feature extraction, this model is characterized by strong nonlinear feature fitting ability. Experiments on multiple datasets show that with an effect similar to that of other models established based on the decision-making tree algorithm, e.g. LGB and XGB, this model can output the risk value corresponding to each feature and feature combination and then deploy these values through the decision-making engine.
-
Automatic
feature generation engine
Based on the first-mover advantage of Cloudwalk in the field of AI engineering, the automatic feature generation engine automatically generates the candidate features of the subject to be predicted by simply configuring the Meta information of the data and its aggregate statistics. This engine can generate corresponding experience based on the actual features summarized by algorithm engineers in a variety of scenarios. Only by simply configuring the Meta information of tabular time series log data, a set of high-level baseline features can be obtained automatically.
-
Machine
learning training engine
Cloudwalk has independently researched and developed a model training platform for algorithm engineers. By inputting the training dataset and adjusting the model parameters and label features, algorithm engineers can complete the model training and publish the model to the inference platform. There are three types of machine learning algorithms, i.e. supervised, semi-supervised and unsupervised algorithms, which are used to solve the following problems: classification (supervised and semi-supervised algorithms), regression (supervised algorithms) and classification (unsupervised algorithms). Users can train self-developed algorithms on the training platform by uploading the configuration files and the input and output codes of the algorithms.
-
Machine
learning inference engine
Relying on Cloudwalk’s constant accumulation in AI engineering, the models produced in the training platform are deployed to provide online reasoning services for downstream platforms/engines (e.g. decision-making engines and external scheduling systems).
The machine learning inference engine developed by Cloudwalk features multiple strengths: based on distributed model deployment architecture; support mainstream inference frameworks; support the rapid integration of third-party tools and models.





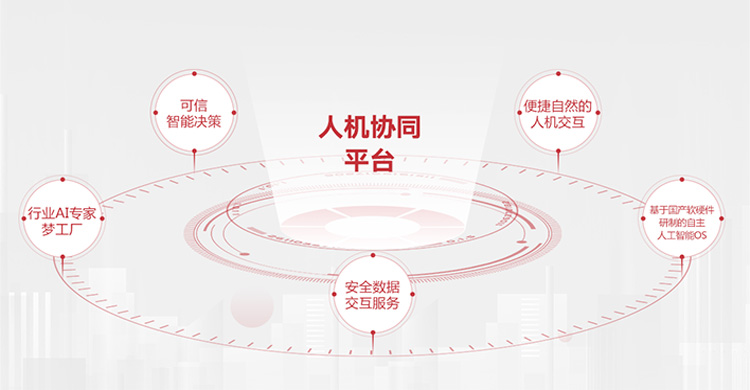
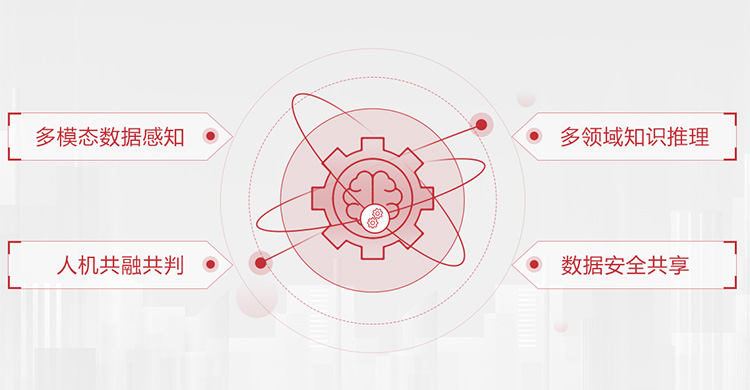
 man-machine
man-machine man-machine
man-machine man-machine
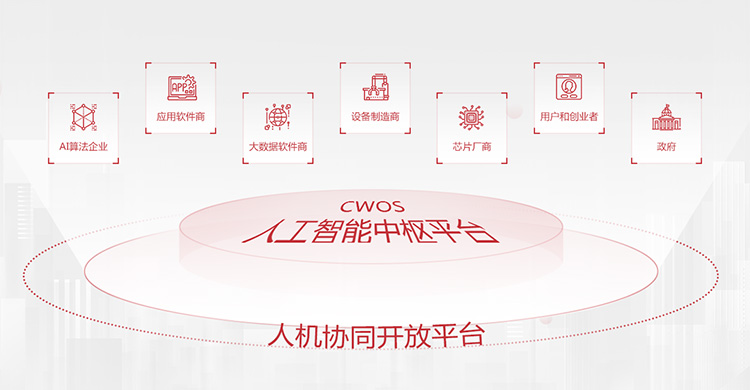
man-machine AI algorithm
AI algorithm Application
Application Big data software
Big data software Equipment
Equipment Chip
Chip Users and
Users and Government
Government