云从科技斩获ICCV2023细粒度行为检测挑战赛冠军 打造多模态技术闭环
近日,ICCV2023 细粒度行为检测挑战赛(Open Fine Grained Activity Detection Challenge)顺利结束,云从科技在行为分类赛道(以下简称OpenFAD23-ICCV23)中斩获冠军。
挑战赛中,云从从容大模型展示了对多种模态信息的优秀理解和处理能力,从早稻田大学、软银等国内外多家知名企业、科研机构中脱颖而出,刷新世界纪录,再次展示了云从科技在多模态大模型领域的技术实力。
表1: 云从科技在OpenFAD23-ICCV23数据集上的表现
专注领先技术研发 推动视觉大模型落地应用
3D行为识别技术相比2D图像识别增加了时间维度的建模,是以人为中心的感知任务的重要组成部分,一直是人工智能领域的研究热点。

大模型具有强大的表征能力,并且在多模态(如语言、音频、图像、视频、视觉语言)上得到验证,云从结合实际业务落地需求研发了基于时空建模的3D行为识别基础大模型。
该模型基于Vision Transformer结构进行设计,通过自注意力机制将空间维度和时间维度的信息进行充分关联。
在预训练阶段,采用掩码重建的方式进行自监督学习,为了让模型同时学到场景语义和时序动作,采用偏场景的多模态语义特征和偏时序的动作特征同时做为教练模型(teacher)进行多分支特征蒸馏,使得模型同时具有场景语义和时序动作理解能力。
基于大模型预训练获得的基础时空特征,能够广泛用于视频检索、视频问答、3D行为识别、行为关键帧检测等下游任务中。在下游任务微调(fine-tune)阶段,通过帧间信息互补的方式自适应去除模型冗余的部分,极大提升了下游任务的训练和推理速度。
表2:云从科技在3D行为识别领域权威数据集Something-Something V2上的表现
本次OpenFAD23-ICCV23数据集包含491个日常生活中的人类行为,部分行为之间只有极其微小的差别,需要从视频中抽取多帧画面并采用3D时空建模算法进行分析。
云从科技从容大模型凭借在视觉领域的深厚积累,在OpenFAD23-ICCV23数据集粗粒度(coarse)行为类别上精度达到93.87%,在细粒度(fine-grain)行为类别上精度达到91.96%,识别精度相比上一届OpenFAD22的冠军方案高出4%以上。
准确率的大幅提升表明大模型在时空关系特征建模上的优势,意味着3D行为识别算法已经迈入多模态大模型时代,将极大提升该技术的商业应用价值。目前,该技术已在金融、安防等领域得到了广泛应用,例如人员动作合规识别,打架、跌倒等行为检测。
多次刷新纪录 构建多模态大模型技术闭环
今年以来,云从科技多次在多模态领域实现技术突破。
6月
云从在CVPR 2023提出视觉大模型自监督学习方法,仅需过往1%的数据量或者无需真实数据便可以达到相同的效果;
7月
云从行人基础大模型在PA-100K、RAP V2、PETA、HICO-DET四个数据集成为世界第一,商品基础大模型在MUGE、Product1M 两个规模最大的开源中文多模态商品检索数据集上刷新世界纪录;
8月
云从视觉-语言跟踪大一统模型在4个富有挑战性的跨模态数据集(TNL2K, LaSOT, LaSOTExt, WebUAV-3M)上刷新了四项世界纪录;
这使得从容大模型能够以更好的交互性能,应用于金融、安防、政务、交通、能源、教育、医疗、文娱等行业领域。
那么多模态到底意味着什么?
当你输入一张照片,并用语音或文字“指挥”AI将其部分抠图修改,并发送给朋友时,它能立即理解并完成指令。
多模态交互降低了AI使用的门槛,使AI有望成为万千大众都能使用的生产工具和个人助理。
如今,多模态大模型已成为大模型迈向通用人工智能(AGI)目标的下一个前沿焦点,云从科技持续专注多模态技术研发与储备,推动视觉、语言、音频等技术的边界融合,为更多行业带来创新与变革。
您可能感兴趣
-
 2023-06-27
2023-06-27云从科技及联合研究团队的论文《PointCMP: Contrastive Mask Prediction for Self-supervised Learning on Point Cloud Videos》(基于掩码预测的点云视频自监督学习)成功入选。
-
 2023-06-27
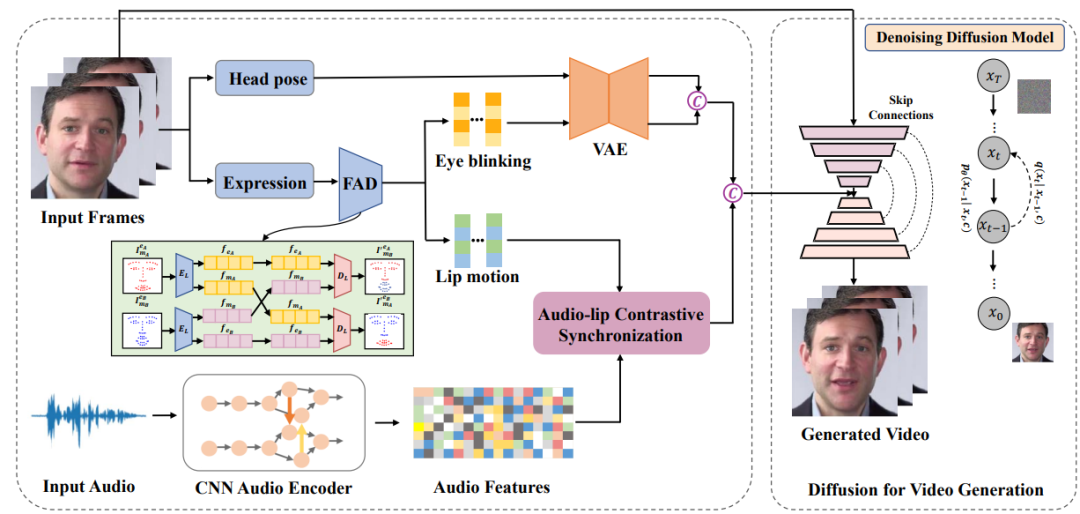
2023-06-27云从科技与上海交通大学联合研究团队的《基于扩散模型的音频驱动说话人生成》成功入选会议论文,并于大会进行现场宣讲,获得多方高度关注。
-
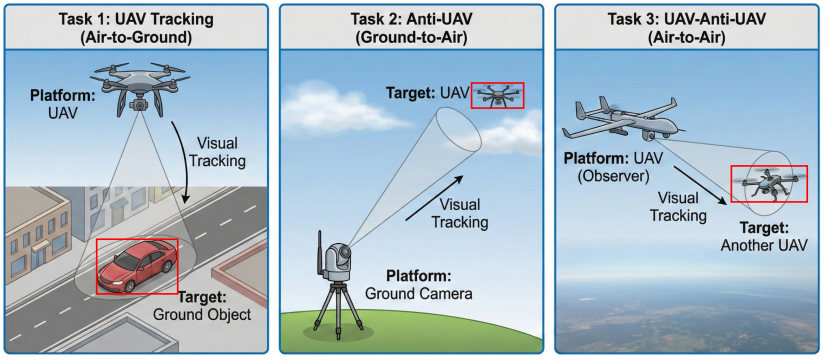 2025-12-12
2025-12-12当追踪者和目标都在低空高速飞行,传统的视觉追踪算法还能跟得住吗? 近日,来自云从科技、上海交通大学、香港科技大学(广州)、中山大学、中国科学院信息工程研究所的联合研究团队发布了一项硬核工作——UAV-Anti-UAV。这是业界首个针对“空对空”(Air-to-Air)场景的百万级多模态反无人机视觉追踪基准,并提出了基于Mamba的强力基线MambaSTS。MambaSTS在UAV-Anti-UAV基准的全部5个指标上均取得最佳的性能,这是云从科技在多模态大模型方面的又一次技术突破。面对双重动态干扰,现有的SOTA表现如何?让我们一探究竟!







