

-
 2025-11-27
2025-11-2711月26日,由中央广播电视总台和上海市人民政府共同主办的2025科创大会在上海开幕。这场以"科创领航,智启新程"为主题的大会,汇聚了来自政府、学界、企业界的重磅嘉宾,共同探讨科技革命与产业变革的核心趋势。 全国人大常委会副委员长郑建邦,中宣部副部长、中央广播电视总台台长慎海雄,上海市委副书记、市长龚正等出席开幕式并致辞。 在当天下午举行的"数智赋能 价值洞见"圆桌论坛上,云从科技董事会秘书杨桦的发言,为这场高规格的技术研讨注入了一股务实之风。
-
 2025-11-26
2025-11-26从天津港全球首个港口大模型PortGPT的成功应用,到此次在湖北工业互联网大会上的方案输出,云从科技正以“AI+场景”的扎实路径,推动工业互联网从“连接赋能”向“认知驱动”升级。
-
 2025-11-03
2025-11-03在位于重庆两江新区的云从科技内,一项旨在重塑区域产业智能格局的战略工程——“重庆市产业大模型与智能体系统产业创新综合体” 正加速推进,成为本地高新技术企业争相观摩学习的标杆。
-
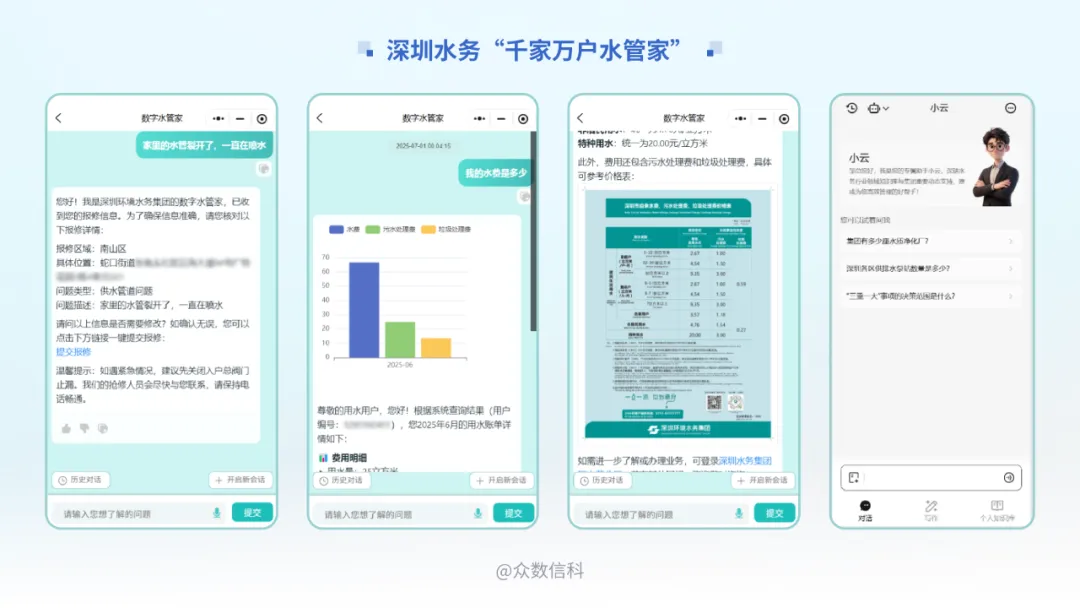 2025-10-28
2025-10-28作为企业级AI智能体基础设施与服务领军者,云从科技子公司众数信科携手深圳环境水务集团(以下简称“深圳水务”)给出了创新答卷——共建“千家万户水管家”智能体!该智能体覆盖459名水管家、7160个小区、322万用户,搭建起用户、水管家、管理者三者协同增效的智慧服务生态,实现水务服务从“主动服务”到“智能化服务”全面升级!
-
 2025-10-23
2025-10-2310月23日,在重庆举行的中德智能制造科技创新合作论坛暨联盟年度大会上,一场关于“工业大模型与工业智能”的研讨引发了行业关注。 云从科技副总裁张立以“复杂场景下的多智能体协同”为主题发表演讲,其中青山工业落地应用的十大AI智能体案例,成为现场的焦点。 在当前智能制造浪潮中,一个核心矛盾日益凸显:许多看似“万能”的通用大模型,一旦进入工厂车间,常常出现“水土不服”。工业场景要求的绝对精准、深度专业和实时响应,恰恰击中了通用大模型的软肋。
-
 2025-09-30
2025-09-30近日,国家标准化管理委员会正式公示“上海虚实融合具身智能训练场标准化试点”项目。 作为全国首个具身智能领域的国家级标准化试点,这一项目不仅标志着我国在人工智能前沿阵地的关键突破,更以“标准统一、生态共建”为核心,为具身智能技术的规模化应用按下加速键。 云从科技作为生态伙伴之一,深度参与这一里程碑式的产业协作网络,与各方共同推动技术标准与场景实践的深度融合。







