

-
 2025-11-03
2025-11-03在位于重庆两江新区的云从科技内,一项旨在重塑区域产业智能格局的战略工程——“重庆市产业大模型与智能体系统产业创新综合体” 正加速推进,成为本地高新技术企业争相观摩学习的标杆。
-
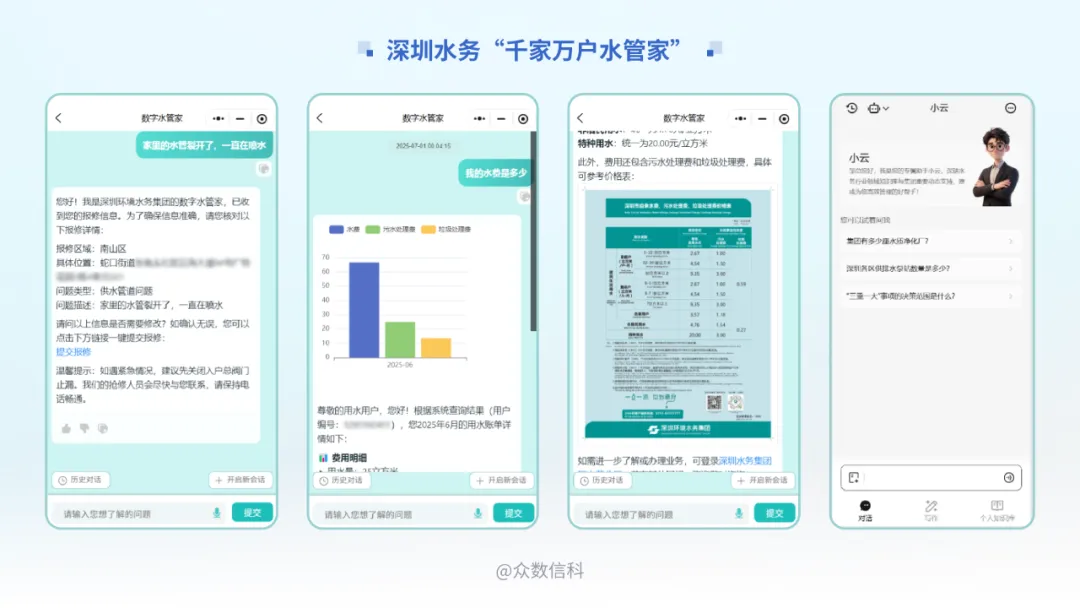 2025-10-28
2025-10-28作为企业级AI智能体基础设施与服务领军者,云从科技子公司众数信科携手深圳环境水务集团(以下简称“深圳水务”)给出了创新答卷——共建“千家万户水管家”智能体!该智能体覆盖459名水管家、7160个小区、322万用户,搭建起用户、水管家、管理者三者协同增效的智慧服务生态,实现水务服务从“主动服务”到“智能化服务”全面升级!
-
 2025-10-23
2025-10-2310月23日,在重庆举行的中德智能制造科技创新合作论坛暨联盟年度大会上,一场关于“工业大模型与工业智能”的研讨引发了行业关注。 云从科技副总裁张立以“复杂场景下的多智能体协同”为主题发表演讲,其中青山工业落地应用的十大AI智能体案例,成为现场的焦点。 在当前智能制造浪潮中,一个核心矛盾日益凸显:许多看似“万能”的通用大模型,一旦进入工厂车间,常常出现“水土不服”。工业场景要求的绝对精准、深度专业和实时响应,恰恰击中了通用大模型的软肋。
-
 2025-09-30
2025-09-30近日,国家标准化管理委员会正式公示“上海虚实融合具身智能训练场标准化试点”项目。 作为全国首个具身智能领域的国家级标准化试点,这一项目不仅标志着我国在人工智能前沿阵地的关键突破,更以“标准统一、生态共建”为核心,为具身智能技术的规模化应用按下加速键。 云从科技作为生态伙伴之一,深度参与这一里程碑式的产业协作网络,与各方共同推动技术标准与场景实践的深度融合。
-
 2025-09-11
2025-09-112025年9月8日,由亚洲银行家集团银行学院主办的“2025中国 AI 创新之旅”在上海正式启程。本次活动汇聚了超过30位全球银行家代表,将走访中国领先的科技与金融企业。云从科技作为人工智能领域的标杆企业,荣幸成为本次创新之旅的首站参访点。
-
 2025-09-08
2025-09-08重庆国际博览中心欢悦厅内,一道智能制造的新曙光正在绽放。 近日,在2025世界智能产业博览会重庆市工业智能体首发仪式现场,云从科技重磅发布经营决策-产线运营智能体,为制造业的智能化转型提供了全新的解决方案。 该智能体的亮相,不仅代表着人工智能技术在工业领域的深度应用,更标志着制造业从"经验驱动"迈向"数据驱动"的重要转折。







